

June 3, 2022, 3:00 AM EDT
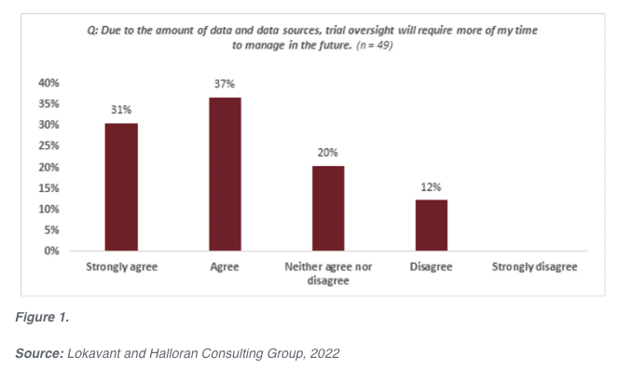
NEW YORK, June 3, 2022 /AppliedClinicalTrials/ -- Due to more complex protocols and increasing data sources, clinical trials are generating triple the amount of data than the previous decade, with an anticipated rise over the next few years.1,2 This influx of study data isn’t necessarily a drawback; on the contrary, it is a great achievement for the clinical research industry, assuming the data is being leveraged by study sponsors and CROs to be proactive in their clinical trial development and operations. However, the rapid increase in data and disparate data sources has left the industry rather stunned. How do we accurately and efficiently manage this influx of critical study data?In addition to the volume and diversity of study data, the quality is also of concern. In a study conducted by Harvard Business Review, 97% of critical data used in business decisions contains errors or is incomplete.3 Another study found that most executives are not confident enough in the accuracy of their data and analytics to take data-driven actions.4 More troubling, the United States, alone, wastes approximately $3.1 trillion on poor-quality data.5 Poor data quality equates to more than just monetary loss; for researchers it means critical time lost due to the need for manual rectification, all while attempting to stay on target with strict deadlines. Additionally, it can lead to insufficient data to assess the endpoints, resulting in delayed or complete absence of submission. But who pays the ultimate price for the increased cost and time spent? The patients relying on life-saving therapies, devices, and vaccines. Lokavant and Halloran Consulting Group conducted a poll with leading biotech executives in clinical development to understand the state of clinical trial data quality, contributing factors, and how sponsors are rising to the challenges of data management. While data quality and management issues are certainly prevalent today, managing studies will only become more difficult in the future—68% of biotech executives said that they expect to spend more time on study oversight due to growing data complexity (see Figure 1 below).
Reasons for poor data quality
While the clinical research industry spends a tremendous amount of effort ensuring the collection of high-quality clinical data, the same cannot be said for the operational data in a study. With a diverse set of tools and processes for data collection and analysis comes an abundance of imprecision. What causes this level of inaccuracy in operational data?
Lack of industry standards: The clinical research industry is filled with numerous data capture systems, unique processes and definitions, resulting in data management chaos. The same data element can vary between different studies, systems, and teams on the same study. The industry tends to overlook data governance, which involves alignment on data definitions to ensure high-quality operational data and compliance throughout the lifecycle of the study. For example, "study start” is a term used by many organizations but has varying definitions. Some organizations may define this as the date when a patient is first screened in a study; others may define this as the date when the first site is activated. The same is true for many other study milestones, both clinical and non-clinical.
Lack of appropriate skillsets: Many clinical trial managers have not had the statistical training to manage the operational and clinical data influx. They are typically tasked with understanding the nuances of the data but lack critical skills required to interpret and analyze the data at scale. With the rise of artificial intelligence (AI) in clinical operations, highly sophisticated algorithms are used to detect highly nuanced signals in large sets of study data. However, these technological advances are only valuable if they can be interpreted by the study operator within the appropriate context. In this nascent but rapidly developing field, the skillsets required to interpret these complex AI algorithms are often lacking, and clinical teams typically do not have the resources to keep up with the latest developments in AI.
Lack of automation and integration: Most biotech executives continue to heavily rely on dashboards and spreadsheets to review study oversight metrics (see Figure 2 below). While these tools offer many advantages, problems occur when spreadsheets and dashboards are used as business intelligence tools by many concurrent users. This can lead to siloes where the data are processed, analyzed, and altered outside a single source, creating multiple versions of truth.
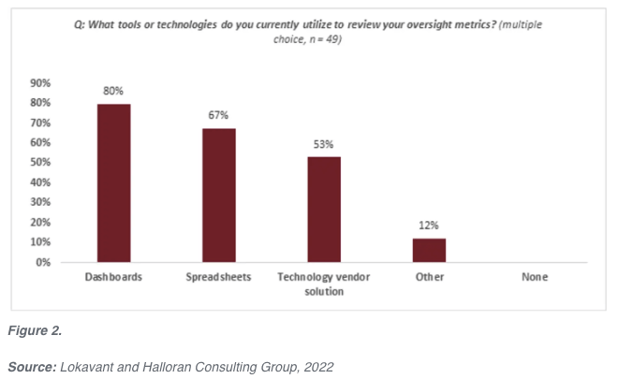
If the available tools to aggregate and standardize data are not utilized, processes will take significantly more time to manage. Eliminating manual processes with a clinical intelligence platform will significantly reduce the exerted effort and improve data quality by maintaining a single space for users to easily access and analyze data. The need for integration and automation is particularly crucial when data are being generated by many unique sources, a commonality across the clinical research industry. For example, hybrid or decentralized clinical trials (DCT) may generate data from remote monitoring technologies, patient self-reporting, site-based data collection, and many other sources. With numerous data sources enters the risk of multiple versions of the same data points. The ability to access study data from a single platform will reduce the need for significant reconciliation and allow for speedier, improved decision-making.
Data not central to decision making: There is a cultural tendency in drug development to make decisions based on hearsay rather than data. For example, one myth that has circulated throughout the industry is that 20% of clinical trial sites will fail to enroll a single patient. This narrative has been widely accepted and relied upon to make critical decisions in study enrollment predictions. However, Tufts Center for the Study of Drug Development compiled an analysis of multiple clinical studies and concluded that only 11% of sites fail to enroll a single patient.6 Furthermore, this percentage can vary based on the therapeutic area or even the location of the study, providing more emphasis on leveraging contextually relevant data to drive critical study decisions. Many organizations have the relevant historical study data and outcomes to forecast future performance more precisely. However, the effort required to systemically capture these insights is often too onerous, causing teams to default to heuristics, industry norms, or personal experience.
Quality clinical data in practice
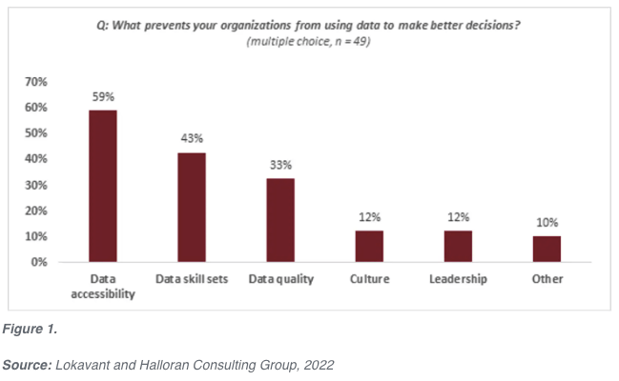
While culture and leadership are key enablers to better decision making, issues related to accessibility, skillsets, and quality are the primary roadblocks for biotech executives (see Figure 3 below). By realizing operational data problems exist, organizations can implement better practices to make improvements.
For most organizations, the root cause of these data issues will be a combination of poorly defined standards, a lack of integrated systems, and a skills gap with respect to advanced analytics. While organizations often look to solve each of these drivers separately, the most effective solution tends to be an integrated approach that addresses these drivers simultaneously.
Whether in-house or through technology partners, operators in clinical studies should adopt master data management principles in parallel to deploying an integrated platform that sets those principles into practice. This requires a data layer that allows study teams to continue their use of disparate systems, but harmonizes data across these systems, studies, and processes. While this represents an initial investment, it is more cost-effective to be proactive in generating high-quality, precise data than to later identify inaccuracies for resolution. Creating a single source of truth will have an immediate impact of reducing reconciliation effort while ensuring better data quality.
Additionally, this high-quality data infrastructure allows organizations to unlock the value of more advanced data analytics, like artificial intelligence, to further augment data quality in increasingly large, complex clinical trial datasets. These analytics can support a wide-range of processes, from early risk detection and mitigation to risk-based quality management, to medical monitoring, to more effective study planning and forecasting—all of which lead to better data quality and improved study outcomes.
Since study teams may not have the expertise to interpret the output of these sophisticated algorithms, sponsors and CROs should consider platforms that are both intelligent and intuitive, allowing study teams to act within their familiar workflows rather than learning new statistical skillsets on a regular basis.
The challenges of data management and quality will continue to soar if the industry remains complacent. Ensuring high quality data in clinical research is paramount; the consequences of ill-informed decisions not only add to the ballooning costs in healthcare but could delay or preclude life-saving therapies to those who need them most.
This is the second in a series of articles where we explore how companies are harnessing and leveraging operational and clinical data to maintain quality and choice. Stay tuned for additional articles with useful insights on data-driven approaches in risk management, vendor oversight and portfolio management.
References
- https://www.globenewswire.com/news-release/2021/01/12/2157143/0/en/Rising-Protocol-Design-Complexity-Is-Driving-Rapid-Growth-in-Clinical-Trial-Data-Volume-According-to-Tufts-Center-for-the-Study-of-Drug-Development.html
- https://www.businesswire.com/news/home/20171107005745/en/Industry-Research-Shows-97-of-Companies-to-Increase-Use-of-Real-world-Patient-Data-for-More-Accurate-Decision-making
- https://hbr.org/2017/09/only-3-of-companies-data-meets-basic-quality-standards
- https://www.cio.com/article/236500/executives-still-mistrust-insights-from-data-and-analytics.html
- https://hbr.org/2016/09/bad-data-costs-the-u-s-3-trillion-per-year
- https://www.globenewswire.com/news-release/2013/01/15/1187761/0/en/New-Research-From-Tufts-Center-for-the-Study-of-Drug-Development-Characterizes-Effectiveness-and-Variability-of-Patient-Recruitment-and-Retention-Practices.html